
You are probably familiar with this scenario already: ask the same AI tool the same question twice, on two different days, and you may get two different answers. Most finance teams have run into this without having a name for it. The number changes by a percentage point or two, even though nobody touched the data, and the explanation that comes back is some version of “the model interpreted it slightly differently this time”. That sentence should worry a CFO more than it usually does, because it points directly at the distinction this explainer is about: whether the system producing your numbers is deterministic or non-deterministic, and what each of those terms actually means once you get past the vocabulary.
Defining Deterministic and Non-Deterministic
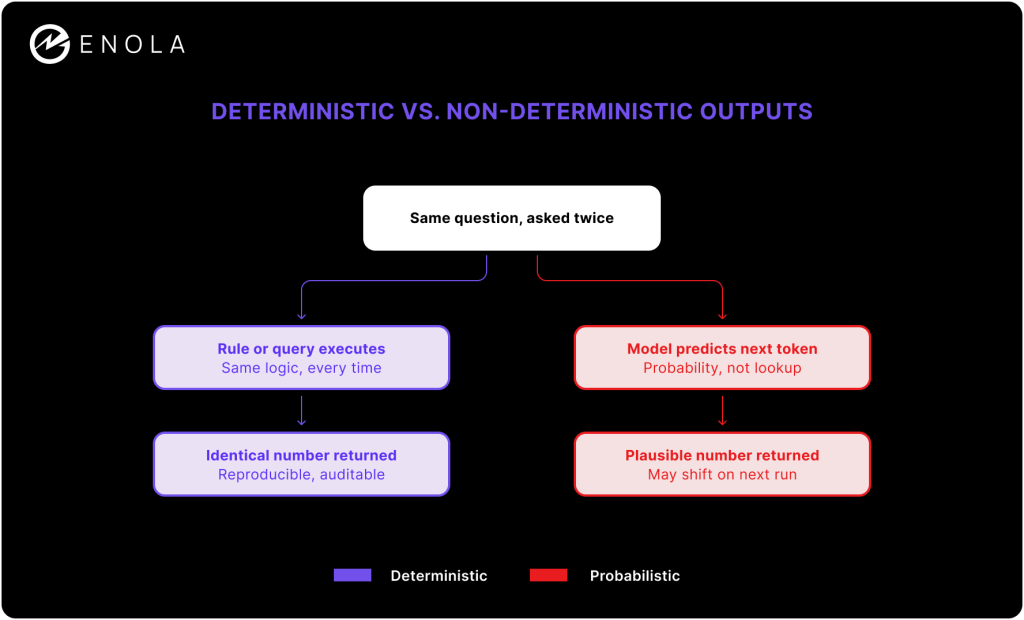
A deterministic system is one where the same input always produces the same output, every time, with no exceptions. A spreadsheet formula is deterministic. A SQL query against an unchanged dataset is deterministic. Compound interest calculated with a fixed rate and term is deterministic. There is no step in the process where the system makes a judgment call about what the answer should be. It executes a rule.
A large language model does not work this way. When an LLM generates a response, it is not retrieving an answer. It is predicting, one token at a time, which word is statistically most likely to come next given everything that came before it. A parameter called temperature controls how much randomness gets injected into that selection. Set it high, and the model takes more liberties, choosing less probable next-words for variety. Set it low, and the model sticks closer to the highest-probability path.
The common assumption is that setting temperature to zero eliminates randomness entirely and makes the model deterministic. This turns out not to be reliably true. Anthropic’s own documentation states it directly: even with temperature set to 0, the results will not be fully deterministic and identical inputs may produce different outputs across API calls. The reasons are technical, things like floating-point arithmetic that isn’t perfectly associative across different hardware paths, or how requests get batched and processed alongside other requests on shared infrastructure. The point for a CFO isn’t to understand the floating-point math. It’s to understand that “we set the temperature to zero” is not the same claim as “this system is deterministic,” no matter how often the two get conflated in a vendor pitch.
This matters because the entire value proposition of determinism rests on a guarantee, not a tendency. A system that’s deterministic ninety-nine times out of a hundred isn’t deterministic. It’s a probabilistic system that happens to be consistent most of the time, which is a meaningfully different and much weaker claim.
Non-determinism isn’t the villain here
It would be easy to write the rest of this piece as a case against probabilistic AI altogether, but that argument isn’t the one worth making. Non-determinism is a feature in a large number of contexts. If you ask a model to draft three versions of a board email, you want variation between the drafts, not three identical copies. If you ask it to summarize a long document, slight differences in phrasing across runs are irrelevant because the underlying meaning is what matters, not the exact words chosen. If you ask it to brainstorm explanations for a variance you’ve already confirmed, multiple framings of the same idea can actually be useful.
The failure mode isn’t probabilistic generation. It’s probabilistic generation applied to a task where the answer needs to be exactly reproducible and where a small drift in token selection translates directly into a different number landing on a board slide. Those are two different categories of task, and most of the confusion in how AI gets deployed in finance comes from treating them as one.
Why finance specifically cannot tolerate it where it matters
Finance is one of the few business functions where the underlying discipline assumes reproducibility as a starting condition. Double-entry bookkeeping, GAAP, the entire architecture of an audit, all of it depends on the premise that given the same transactions and the same rules, two people will arrive at the same number. That assumption is what makes a number auditable in the first place. If the number could legitimately come out differently depending on when you asked or which run of the model happened to fire, there is no stable thing for an auditor to test against.
This isn’t an abstract concern. Auditing standards have already caught up to the question of how reliable a number needs to be when it was produced by a company’s own systems, AI or otherwise. Under PCAOB Auditing Standard 1105, when information produced by the entity is used as audit evidence, auditors are required to evaluate whether that information is accurate, complete, and sufficiently precise for the purpose it’s being used for, which in practice means testing the underlying data and the process that produced it, not just accepting the output at face value. A number that can’t be regenerated identically on demand makes that testing significantly harder, because there’s no fixed artifact to test against. You’re not auditing a calculation anymore. You’re auditing a moment.
The accounting standard-setters have started addressing generative AI directly rather than leaving finance teams to extrapolate. In February 2026, COSO released formal guidance on internal control over generative AI, building on the same Internal Control Integrated Framework that underpins SOX compliance. The guidance is explicit about why this needed its own treatment: generative AI represents a shift from deterministic, rule-based technology toward probabilistic systems with inherent variability, and that shift changes what counting on a control actually means. A control built around a deterministic process can be tested once and trusted to behave the same way next quarter. A control built around a probabilistic process needs continuous monitoring, because the same prompt next month, run against an updated model, is not guaranteed to behave the way it did when you first validated it.

None of this is a reason to avoid AI in finance. It’s a reason to be precise about which layer of your workflow you’re allowing to be probabilistic, because the regulatory environment is now treating that distinction as material, not theoretical.
How to actually find out which kind of system you’re using
Most procurement conversations never get specific enough to answer this. A useful test is simple to run.
Ask the vendor to execute the identical query twice in separate sessions and compare the underlying numbers, not just the surrounding sentences, since two responses can use different words around an identical figure and that’s fine. What you’re checking for is whether the number itself moves. Then ask a more pointed question: when I ask for a metric, does the model calculate it, or does it run a defined query and then describe the result. Those are architecturally different things even when the user experience looks identical, and a vendor who can’t answer the question cleanly is usually telling you something important by the hesitation alone.
Here’s a detailed guide by Piyanka Jain that finance teams can use to evaluate AI vendors
This is also where the distinction in how agentic AI actually makes decisions in analytics workflows becomes directly relevant. An agent that decides which tool to call, which query to run, and how to sequence a workflow can still produce numbers that are fully deterministic, provided the actual computation at the end of that chain is a fixed rule rather than a generated guess. The agentic layer and the deterministic layer aren’t in conflict. They’re doing different jobs, and the architecture only works if you keep them separated.
Where the line belongs, and how AskEnola draws it
The architecture worth building toward, and the one AskEnola is built around, keeps a hard separation between the two layers. The actual analytics, the SQL execution against your warehouse, the business logic that defines what MRR or churn or gross margin means in your specific business, runs deterministically. None of that math is generated by a language model. The model’s role sits entirely in the conversational layer: understanding what you’re asking for, translating it into the right query or workflow, and writing the narrative around a result that was already computed by a rule before the model ever touched it. Ask the same question twice, get the same number twice, because the number was never the model’s to decide in the first place. The workflow automation layer that sits on top of this, generating the QBR pack or refreshing a forecast on a schedule, follows the same principle: it’s orchestration of deterministic computation, not computation performed by the model itself.
This is also, not coincidentally, the same architectural posture we made the case for when writing about what real-time, decision-ready analytics actually requires under the hood. Speed and determinism aren’t in tension. The fastest path to a trustworthy number is usually the one that skips the generation step entirely and goes straight to the rule.
The standard worth holding AI to
The question to ask any finance tool isn’t whether it uses AI. Almost everything does now. The question is where, specifically, in the path between your raw data and the number on your board slide, a probabilistic step is doing work that should belong to a deterministic one. That’s not a question most demos are built to answer cleanly, which is exactly why it’s worth asking directly, and why the answer tells you more about the tool than anything else in the pitch.